
基于频域卷积传递函数的盲源分离研究获得进展
盲源分离是指仅利用传声器接收到的信号把各个源信号恢复出来。音频信号的盲源分离最初是为解决“鸡尾酒会问题”发展起来,它在人机语音交互、自动会议纪要、人声和配乐分离等方面有潜在的重要应用价值。
目前,流行的音频盲源分离算法例如频域ICA(independent component analysis)、频域IVA(independent vector analysis)和ILRMA(independent low-rank matrix analysis)等都是依赖于秩1的空间模型。该模型基于窄带假设,也就是短时傅里叶变换的窗长远大于混响时间。当混响时间变长时,上述这类盲源分离算法的性能严重下降。为了解决该问题,FCA(full-rank covariance matrix analysis)、MNMF(multichannel nonnegative matrix factorization)和Fast MNMF等算法将空间模型强制约束为一个满秩的矩阵,并在强混响环境下取得了性能的提升。但是,满秩空间模型只是数学上的一个假设,缺乏明确的物理意义和严格的数学推导。
近期,中科院声学所噪声与音频声学实验室的博士生王泰辉和导师杨飞然研究员、杨军研究员提出了一种基于频域卷积传递函数的盲源分离框架。不同于以往广泛采用的窄带假设,他们利用频域卷积传递函数模型来建模时域的线性卷积,建立了一种全新的音频盲源分离框架。研究人员证明上述满秩空间模型可以利用所提新框架和声源信号慢变化这一近似条件推导出来,解释了满秩模型在强混响场景性能较好的原因。基于所提框架,研究人员还提出了一种新的多通道非负矩阵分解算法。实验证实这种超定盲源分离算法在强混响场景下比当前的盲源分离算法(ILRMA和FastMNMF)具有更好的分离性能和语音质量。
该项研究为解决强混响条件下的音频盲源分离提供了一个新思路。
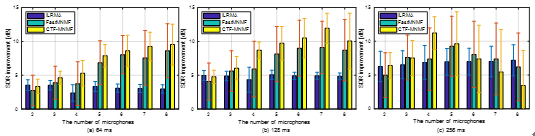
图1 两声源分离实验中在混响时间Rt60=470毫秒时不同算法的SDR提升。短时傅里叶变换窗长为(a) 64毫秒,(b) 128毫秒,(c) 256毫秒。(图/中科院声学所)
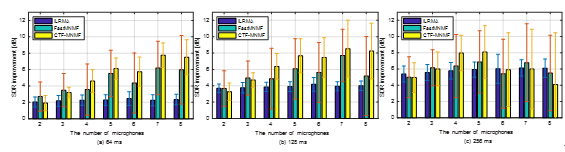
图2 两声源分离实验中在混响时间Rt60=1300毫秒时不同算法的SDR提升。短时傅里叶变换窗长为(a) 64毫秒,(b) 128毫秒,(c) 256毫秒。(图/中科院声学所))
本研究获得了国家自然科学基金面上项目、中国科学院青年创新促进会和中国科学院声学研究所自主部署“前沿探索”类项目资助。
相关研究成果于2022年1月在线发表于国际期刊IEEE/ACM Transactions on Audio, Speech, and Language Processing。
关键词:
盲源分离;卷积传递函数;非负矩阵分解;空间模型
参考文献:
T. Wang, F. Yang, and J. Yang, “Convolutive transfer function-based multichannel nonnegative matrix factorization for overdetermined blind source separation,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 30, pp. 802–815, Jan. 2022. DOI:10.1109/TASLP.2022.3145304.
论文链接:

